1.8. Linux Virtual Server
Linux Virtual Server (LVS) is a set of integrated software components for balancing the IP load across a set of real servers. LVS runs on a pair of equally configured computers: one that is an active LVS router and one that is a backup LVS router. The active LVS router serves two roles:
The backup LVS router monitors the active LVS router and takes over from it in case the active LVS router fails.
Figure 1.19, “Components of a Running LVS Cluster” provides an overview of the LVS components and their interrelationship.
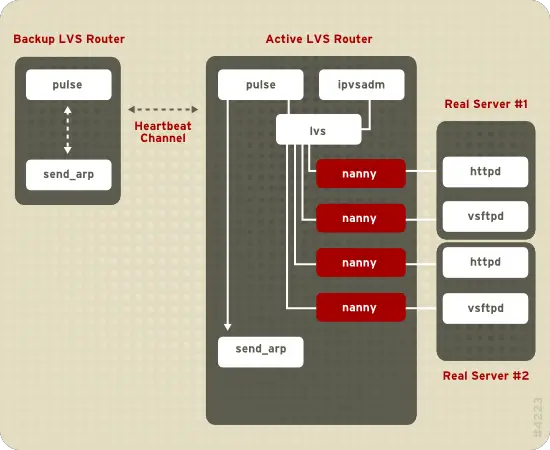
The pulse daemon runs on both the active and passive LVS routers. On the backup LVS router, pulse sends a heartbeat to the public interface of the active router to make sure the active LVS router is properly functioning. On the active LVS router, pulse starts the lvs daemon and responds to heartbeat queries from the backup LVS router.
Once started, the lvs daemon calls the ipvsadm utility to configure and maintain the IPVS (IP Virtual Server) routing table in the kernel and starts a nanny process for each configured virtual server on each real server. Each nanny process checks the state of one configured service on one real server, and tells the lvs daemon if the service on that real server is malfunctioning. If a malfunction is detected, the lvs daemon instructs ipvsadm to remove that real server from the IPVS routing table.
If the backup LVS router does not receive a response from the active LVS router, it initiates failover by calling send_arp to reassign all virtual IP addresses to the NIC hardware addresses (MAC address) of the backup LVS router, sends a command to the active LVS router via both the public and private network interfaces to shut down the lvs daemon on the active LVS router, and starts the lvs daemon on the backup LVS router to accept requests for the configured virtual servers.
To an outside user accessing a hosted service (such as a website or database application), LVS appears as one server. However, the user is actually accessing real servers behind the LVS routers.
Because there is no built-in component in LVS to share the data among real servers, you have have two basic options:
The first option is preferred for servers that do not allow large numbers of users to upload or change data on the real servers. If the real servers allow large numbers of users to modify data, such as an e-commerce website, adding a third layer is preferable.
There are many ways to synchronize data among real servers. For example, you can use shell scripts to post updated web pages to the real servers simultaneously. Also, you can use programs such as rsync to replicate changed data across all nodes at a set interval. However, in environments where users frequently upload files or issue database transactions, using scripts or the rsync command for data synchronization does not function optimally. Therefore, for real servers with a high amount of uploads, database transactions, or similar traffic, a three-tiered topology is more appropriate for data synchronization.